Self-Hosted LLM Inference
No OpenAI. No Claude. No API Keys.
Just a small transformer, language models, lightweight vector database, and services, running inside a small Kubernetes cluster.
Of course, the ability of the LLM inference is so bad.
You can try the live demo with this link: https://ilyasahsan.xyz/chat-server
Introduction
In this post, I'm going to explain the LLM inference setup I built on my own Kubernetes cluster. This includes the Kubernetes manifest files used to define each service. Furthermore, these services are become dependencies for the LLM Inference.
Architecture
It's follow the RAG framework architecture. Find the sequence diagram below:
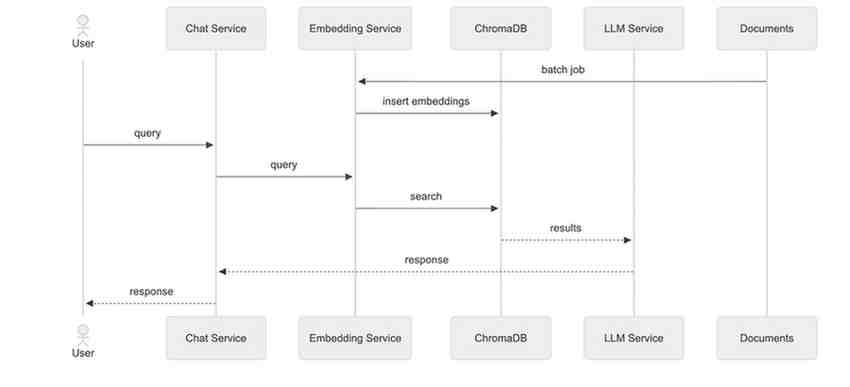
plantuml-sequence-diagram
%%{init: {'theme': 'neutral'}}%%
sequenceDiagram
actor User
participant ChatSvc as Chat Service
participant EmbedSvc as Embedding Service
participant Chroma as ChromaDB
participant LLMSvc as LLM Service
participant Docs as Documents
Docs->>EmbedSvc: batch job
EmbedSvc->>Chroma: insert embeddings
User->>ChatSvc: query
ChatSvc->>EmbedSvc: query
EmbedSvc->>Chroma: search
Chroma-->>LLMSvc: results
LLMSvc-->>ChatSvc: response
ChatSvc-->>User: response
Disclaimer
This post is long, going through a lot of code. Takes your time to reading it.
Don't use for production. It's used simple approach to create and deploy application into the Kubernetes cluster.
The LLM Inference intended only to answer knowledge base below: (details: here)
- Messi scored a hat trick in the World Cup 2026
- Cristiano Ronaldo scored a brace in the World Cup 2026
Prerequisites
Convert the following Models into the GPT-Generated Unified Format (GGUF) format.
- Embedding model: all-MiniLM-L6-v2
- Language model: SmolLM2-135M-Instruct
I converted with the following command:
# Step 1. Install the Huggingface CLI and Login with token.
brew install hf
hf auth login --token <HUGGINGFACE_TOKEN>
# Step 2. Download the Models into the local machine.
hf download sentence-transformers/all-MiniLM-L6-v2 --local-dir ./all-MiniLM-L6-v2
hf download HuggingFaceTB/SmolLM2-135M-Instruct --local-dir ./SmolLM2-135M-Instruct
# Step 3. Clone the llama.cpp repository.
git clone git@github.com:ggml-org/llama.cpp.git
cd llama.cpp
# Step 4. Convert the Models into the GGUF format.
python convert_hf_to_gguf.py ./all-MiniLM-L6-v2 --outfile ~/Downloads/all-MiniLM-L6-v2-f16.gguf --outtype f16
python convert_hf_to_gguf.py ./SmolLM2-135M-Instruct --outfile ~/Downloads/SmolLM2-135M-Instruct.gguf --outtype f16
And then, uploaded into huggingface repository so that it's can be used by the services.
- https://huggingface.co/ilyasahsan/GGUF/blob/main/SmolLM2-135M-Instruct-Q4_K_M.gguf
- https://huggingface.co/ilyasahsan/GGUF/blob/main/all-MiniLM-L6-v2-f16.gguf